LLVM 代码混淆
这里是看雪学院课程LLVM与代码混淆技术的笔记,讲师是@34r7hm4n,讲的很好,希望大家有能力的支持一下原作者。
本文环境与作者稍有不同(WSL Kali + LLVM 16.0.0),作者提供的源代码有许多编译或者运行时会出现错误,本文中对其进行了修改,使之能够正常编译和运行,多数修改部分给出了注释或说明。
LLVM 架构
LLVM 分为前端和后端,前端的输入为源代码,经过词法分析、语法分析和语义分析,输出中间代码(IR)。后端的输入为中间代码,优化器对中间代码进行优化,最后输出目标程序。
编译 LLVM
LLVM 编译可执行文件的过程
LLVM IR 分为人类可阅读的形式(.ll),和易于机器处理的二进制格式(.bc)。首先将 Cpp 源码转化为 LLVM IR:
1 | clang -S -emit-llvm hello.cpp -o hello.ll |
随后使用 opt 对 IR 进行优化:
1 | opt -load LLVMObfuscator.so -hlw -S hello.ll -o hello.opt.ll |
最后编译为可执行文件:
1 | clang hello.opt.ll -o hello |
第一个 LLVM Pass
前置知识
LLVM Pass 框架可以干预代码优化过程,使用 Pass 进行代码混淆。Pass 编译后通过 opt 进行加载,可以对 IR 进行分析和修改,最终影响生成的目标代码。Pass 提供了丰富的 API,可以在文档中查看。
部分重要的文件夹:
- llvm/include/llvm,包含 llvm 提供的公共头文件
- llvm/lib,存放了大部分源代码和部分不公开头文件
- llvm/lib/Transforms,存放了 Pass 的源代码,LLVM 自带了一些 Pass
LLVM Pass 有三种编译方式:
- 与整个 LLVM 一起重新编译,Pass 代码存放到 llvm/lib/Transforms 文件夹中
- 通过 CMake 单独编译,此处使用这种方式
- 通过命令行单独编译
编写 Pass 前需要确定 Pass 的类型,LLVM 有多种类型的 Pass,包括:ModulePass、FunctionPass,CallGraphPass、LoopPass 等。最常用的是 FunctionPass,它以函数为单位进行处理,FunctionPass 的子类必须实现 runOnFunction函数,FunctionPass 运行时会对程序中的每个函数执行 runOnFunction函数。
编写
目标是编写一个输出程序所有函数的 Pass,类型是 FunctionPass。基础步骤:
- 创建一个类,继承
FunctionPass类 - 在创建的类中实现
runOnFunction(Function &F)函数 - 向 LLVM 注册 Pass 类
附编写 Pass 模板:
1 |
|
编译
使用 CMake 将 Pass 编译为 .so 文件。
CMakeLists.txt 为编译
加载
使用 opt 加载编译好的 Pass,处理中间代码,生成新的中间代码。
实践
创建目录结构:
1 | . |
TestProgram.cpp(一个简单的 CTF 逆向题目,Pass 应用的目标):
1 |
|
CMakeLists.txt(管理项目):
1 | project(OLLVM++) |
HelloWorld.cpp(参照模板编写的 Pass):
1 |
|
test.sh(测试脚本,运行即可完成测试):
1 | cd ./Build |
-enable-new-pm=0代表不适用新的 Pass Manager,不使用此选项在使用 opt 加载 Pass 时可能出现Unknown Pass错误。
运行 test.sh 脚本,输入flag{s1mpl3_11vm_d3m0},输出Congratulations,完成第一个 Pass。
LLVM IR
LLVM IR 是一种低级编程语言,类似于汇编,可以方便地进行代码优化。LLVM IR 有两种表示方式,文本形式(.ll)和二进制形式(.bc),两者是等价的,可以通过llvm-dis和llvm-as进行转化。
结构
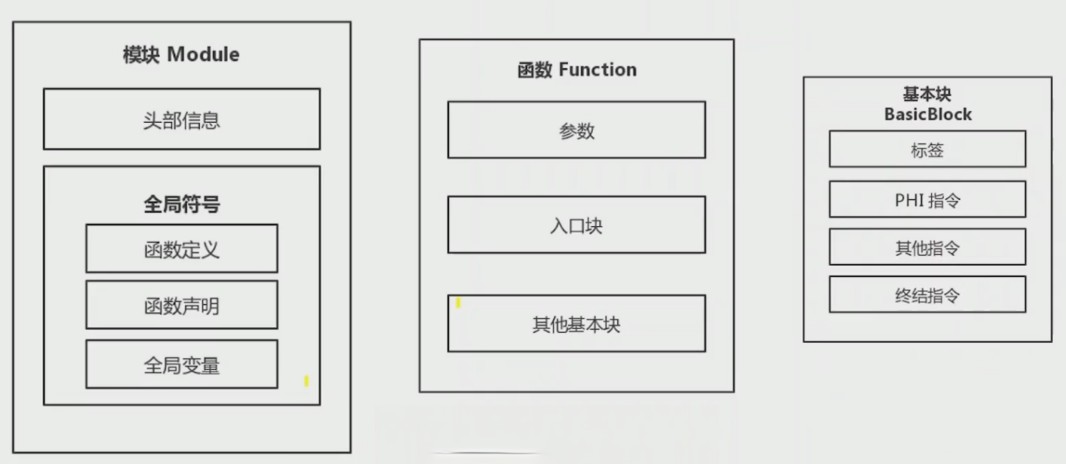
一个模块对应一个源代码文件,模块头部信息包含程序目标平台和一些其他信息。
IR 中的函数对应源代码中的一个函数,一个函数由若干基本块组成,函数最先执行的基本块称为入口块。
基本块由若干指令和标签组成,正常情况下,基本块的最后一条指令为跳转指令(br或switch)或返回指令(retn),也叫做终结指令(Terminator Instruction)。
基于 IR 的代码混淆
基于 IR 的代码混淆主要关注函数或比函数更小的单位:
- 以函数为单位——控制流平坦化
- 以基本块为单位——虚假控制流
- 以指令为单位——指令替代
静态单赋值
静态单赋值(Static Single Assignment,SSA)是 IR 的一个属性,可以简单认为程序中一个变量仅能有一条赋值语句,LLVM IR 基于 SSA 原则进行设计。
为了实现 SSA,C/C++ 中常用的循环如:
1 | for(int i=0; i<100; i++) |
需修改为:
1 | int *i = (int *)malloc(4); |
LLVM IR 中就存在这种方式。
IR 的常用指令
终结指令
ret,对应 C/C++ 中的 return,语法:1
2ret <type> <value> ;返回指定类型的值
ret void ;返回类型为 void实例:
1
2
3
4ret i32, 5 ;返回整数5
ret void ;无返回值
ret { i32, i8 } { i32 4, i8 2 }
;返回结构体br,分为有条件分支和无条件分支,对应 C/C++ 的 if 和汇编中的有条件和无条件跳转指令1
2
3br i1 <cond>, label <iftrue>, label <iffalse>
;条件分支, cond 为真跳转至 iftrue,否则跳转至 iffalse
br label <dest> ;无条件分支实例:
1
2
3
4
5
6
7Test:
%cond = icmp eq, i32 %a, %b
br i1 %cond, label %IfEqual, label %IfUnequal
IfEqual:
ret i32 i
IfUnequal:
ret i32 0switch类似于 C/C++ 中的 switch1
switch <intty> <value>, label <defaultdest> [<intty> <value> label <dest> ...]
实例:
1
2
3
4
5
6
7
8
9
10%Val = zext i1 %value to i32
switch i32 %Val, label %trudest [ i32 0, label %falsedest ]
; 等效于条件跳转
switch i32 0, label %dest []
; 等效于无条件跳转
switch i32 %val, label %otherwise [ i32 0, label %onzero
i32 1, label %onone
i32 2, label %ontwo ]
比较指令
icmp,比较整数或指针1
2
3
4<result> = icmp <cond> <ty> <op1>, <op2>
; cond 可以是 eq(相等),ne(不相等),
; ugt(无符号大于),sle(有符号小于或等于)等等
; ty 是 op1 和 op2 的类型fcmp,比较浮点数1
2
3
4<result> = fcmp <cond> <ty> <op1>, <op2>
; cond 可以为 oeq(ordered and equal),
; ueq(unordered or equal), false(必定不成立),
; ordered 指两个操作数都不是 NaN
二元运算指令
add,整数加法1
<result> = dd <ty> <op1>, <op2>
sub,整数减法1
<result> = sub <ty> <op1>, <op2> ; result = op1 - op2
mul,整数乘法1
<result> = mul <ty> <op1>, <op2>
udiv,无符号整数除法,可以加入exact关键字1
2<result> = udiv <ty> <op1>, <op2> ; result = op1/op2
<reuslt> = udiv exact <ty> <op1>, <op2> ; 如果 op1 不是 op2 的倍数,会出现错误sdiv,有符号整数除法,同样可以加入exact关键字1
2<result> = sdiv <ty> <op1>, <op2> ; result = op1/op2
<reuslt> = sdiv exact <ty> <op1>, <op2> ; 如果 op1 不是 op2 的倍数,会出现错误urem,无符号整数取余1
<result> = urem <ty> <op1>, <op2> ; result = op1 % op2
srem,有符号整数取余1
<result> = srem <ty> <op1>, <op2> ; result = op1 % op2
按位二元运算指令
shl,整数左移1
<result> = shl <ty> <op1>, <op2> ; result = op1 << op2
lshr,整数逻辑右移(左侧补零)1
<result> = lshr <ty> <op1>, <op2> ; result = op1 >> op2
ashr,整数算数右移(左侧补符号位)1
<result> = ashr <ty> <op1>, <op2>
and,整数按位与1
<result> = and <ty> <op1>, <op2> ; result = op1 & op2
or,整数按位或1
<result> = or <ty> <op1>, <op2> ; result = op1 | op2
xor,按位异或1
<result> = xor <ty> <op1>, <op2> ; result = op1 ^ op2
内存访问和寻址操作指令
alloca,在栈中分配一块空间,并获得指向该空间的指针1
2<result> = alloca <type> [, <ty> <NumElement>] [, align <alignment]
; 分配 sizeof(type) * NumElements 字节的内存,分配地址与 alignment 对齐, 指针指向 type 类型实例:
1
2
3%ptr = alloca i32 ; 分配 4 字节内存,指针指向 i32 类型
%ptr = alloca i32, i32 4 ; 分配 4*4 = 16 字节内存 ;
%ptr = alloca i32, i32 4, align 1024 ; 分配的地址与1024对齐store,向指针指向的内存中存储数据1
store <ty> <value>, <ty>* <pointer>
实例:
1
2%ptr = alloca i32
store i32 3, i32* %ptr ; 向 %ptr 指向的的内存写入 3load,从指针指向的内存中读取数据1
<result> = load <ty>, <ty>* <pointer>
实例:
1
2
3%ptr = alloca i32
store i32 3, i32* %ptr
%val = load i32, i32* %ptr ; 从 %ptr 指向的地址读取 3
类型转换指令
trunk .. to,将一种类型的变量截断为另一种类型的变量(从较大的类型到较小的类型)1
<result> = trunc <ty> <value> to <ty2>
实例:
1
2
3%X = trunc i32 257 to i8 ; %X = 1
%W = trunc <2 x i16> <i16 8, i16 7> to <2 x i8>
; %W = <i8 8, i8 7>zext. .. to,将一种类型的变量零拓展为另一种类型(从较小的类型到较大的类型),零拓展后值不会改变1
<result> = zext <ty> <value> to <ty2>
sext .. to,符号拓展,通过复制符号位进行拓展1
<result> = sext <ty> <value> to <ty2>
实例:
1
2
3%X sext i8 -1 to i16 ; -1 = 0b10000001 补码为 11111111
; sext 在高位填充符号位(1)
; 结果为 11111111 11111111 = -1
其他指令
phi,为了解决 SSA 一个变量之恶能被赋值一次的问题产生的指令,其计算结果由 phi 指令所在基本块的前驱块确定1
<result> = phi <ty> [ <val0>, <label0>], ... ; 如果前驱块为 label0,则 result = val0
用 phi 指令可以实现另外一种具有 SSA 属性的 for 循环:
1
2
3
4Loop:
%indvar = phi i32 [ 0, %LoopHeader], [ %nextindvar, %Loop]
%nextindvar = add i32 %indvar, 1
br label %Loopselect,类似三元运算符? :1
2<result> = select i1 <cond>, <ty> <value1>, <ty> <value2>
; cond 为真,则 result = value1,否则为 value2call,调用函数,与 x86 汇编不同在于 IR 的 call 可以传递参数1
<result> = call <ty>|<fnty> <fntrval>(<function args>)
C++
LLVM 使用 C++ 开发,采用 C++ 11 标准开发,并使用了 STL ,需要掌握一定 C++ 基础。
LLVM Pass 常用 API
常用类
Function,获取函数属性,例如名称、入口块,利用 Function 类可以遍历函数中的基本块
1
2
3
4
5bool runOnFunctino(Function &F){
for(BasicBlock &BB:F){
// do something
}
}BasicBlock,可以进行基本块的克隆、分裂、移动等,可以遍历基本块中的指令
1
2
3
4
5
6
7bool runOnFunction(Function &F){
for(BasicBlock &BB:F){
for(Instruction &I: BB){
// do something
}
}
}Instruction,包含一些子类,例如 BinaryOperator,AllocaInst,BranchInst 等,可以对指令进行创建、删除和修改,也可以遍历指令中的操作数
1
2
3
4
5
6
7
8
9bool runOnFunction(Function &F){
for(BasicBlock &BB:F){
for(Instruction &I: BB){
for(int i = 0; i< I.getNumOperands(); i++){
Value *V = I.getOperand(i);
}
}
}
}Value,基本类,所有可以被当作指令操作数的类都是 Value 的子类,包括 Constant,Argument,Instruction,Function,BasicBlock 五个子类。
输出流
LLVM 中建议使用 outs(),errs(),dbgs() 三个输出流
常用文档
文档页面:About — LLVM 16.0.0git documentation
编程手册:LLVM Programmer’s Manual — LLVM 16.0.0git documentation
在 Windows 上搭建环境:Getting Started with the LLVM System using Microsoft Visual Studio — LLVM 16.0.0git documentation
用 CMake 单独编译 Pass:Building LLVM with CMake — LLVM 16.0.0git documentation
编写 Pass,本文内容与这篇关系较大:Writing an LLVM Pass — LLVM 16.0.0git documentation
编写 Pass(使用新的 Pass Manager):Writing an LLVM Pass — LLVM 16.0.0git documentation
介绍 SSA:MemorySSA — LLVM 16.0.0git documentation
API 文档:LLVM: LLVM
命令行工具文档:LLVM Command Guide — LLVM 16.0.0git documentation
LLVM IR 语言参考:LLVM Language Reference Manual — LLVM 16.0.0git documentation
基本块分割
原理
将一个基本块分割为若干个等价的基本块,在分割后的基本块之间加上无条件跳转。
基本块分割可以提高某些代码混淆的效果。
只需遍历每个函数中的每个基本块,对其进行分割即可,其中包含 phi 指令的基本块需要跳过,否则可能发生错误。
使用的 API:
额外参数指定,可以从外部获取自定义参数。在 LLVM 中,可以通过
cl::opt模板类获取指令中的参数,此处 opt 是 option 的缩写。1
2
3
4
// 可选参数,指定一个基本块会被分割为几个基本块,默认为 2
static cl::opt<int> splitNum("split_num", cl::init(2), cl::desc("Split <split_num> time(s) each BasicBlock"));命令行中的使用方法:
1
opt -load ../Build/LLVMObfuscator.so -split -split_num 5 -S TestProgram.ll -o TestProgram_split.ll
splitBasicBlock函数,是BasicBlock类的成员函数,在 BasicBlock.h 中有详细的解释。有两个重载,可以看到它们本质是一样的:1
2
3
4
5
6BasicBlock *splitBasicBlock(iterator I, const Twine &BBName = "",
bool Before = false);
BasicBlock *splitBasicBlock(Instruction *I, const Twine &BBName = "",
bool Before = false) {
return splitBasicBlock(I->getIterator(), BBName, Before);
}此处使用第二种,将基本块以指令 I 为边界分为两个基本块,指令 I 放在后面的基本块中,并在两个基本块之间建立无条件跳转。
BBName为新基本块的名称,Before为 True 时会将第二个基本块放在第一个基本块之前。isa <>,模板函数,用于判断一个指针指向的数据类型是不是给定的类型,此处用于判断一个指令是不是 PHI 指令。
实现
在之前 第一个 LLVM Pass 中的实践部分描述的工程中继续编写,在 Transforms/src 目录新建 SplitBasicBlock.cpp,结构类似于之前的 HelloWorld.cpp。内容如下:
1 |
|
关键在于 split 函数。其中 splitBasicBlock 函数会返回分割生成的第二个基本块的指针。
将新编写的 Pass 编译进模块,修改 CMakeList.txt(只在倒数第二行添加了新编写的源文件):
1 | project(OLLVM++) |
为了方便以后的修改,做一些修改,首先在 Transforms/include 目录下添加 SplitBasicBlock.h 文件:
1 |
|
并在 Transforms/src/SplitBasicBlock.cpp 中添加它的实现:
1 | ... |
这样修改之后,新的 Pass 可以通过llvm::createSplitBasicBlockPass的方式复用基本块分割的 Pass。
随后在 Build 目录下添加 IR 和 Bin 两个文件夹,方便管理。
方便测试,对 TestProgram 也进行修改,使其接受命令行参数:
1 |
|
最后修改 test.sh 测试脚本:
1 | cd ./Build |
代码混淆 与 OLLVM
常见概念
- 代码混淆——将程序转换成一种功能上等价,但是难以阅读和理解的形式的行为。
- 函数——代码混淆的基本单位,一个函数由若干基本块组成,有一个入口块,可能有多个出口块,一个函数可以用一个控制流图表示
- 基本块——由一组先行指令组成,每个基本块有一个入口点(第一条执行的指令)和一个出口点(最后一条执行的指令)。终结指令要么跳转到另一个基本块,要么从函数返回。
- 控制流——代表了一个程序在执行过程中可能遍历到的所有路径。通常情况下反应了程序的逻辑,混淆后的控制流会难以分辨正常逻辑。
- 不透明谓词——混淆者明确知晓,但反混淆者却难以推断的变量。
常见混淆思路
- 符号混淆——将函数的符号去除或者混淆。
- 控制流混淆——混淆程序正常的控制流,使其功能不变的情况下不能反映原此程序的逻辑,包括控制流平坦化、虚假控制流、随机控制流。
- 计算混淆——混淆程序的计算流程或计算流程中使用的数据,使分析者难以分辨某一段代码执行的具体计算,包括指令替代和常量替代。
- 虚拟机混淆——将一组指令集和转化为一组位置的自定义指令集,并与程序绑定的解释器解释执行。
OLLVM
Obfuscator-LLVM 简称(OLLVM),能提供代码混淆和防篡改工具。他提供了三种经典的代码混淆,控制流平坦化(Control Flow Flattening)、虚假控制流(Bogus Control Flow)和指令替代(Instruction Substitution)。OLLVM 在2017 年停止开发,但仍有很大学习价值。
编译
由于长时间停止更新,编译 OLLVM 比较困难,因此使用 docker 容器进行学习。
1 | docker pull nickdiego/ollvm-build |
在 docker-ollvm/ollvm-build.sh 第 150 行(docker run之前),加入:
1 | DOCKER_CMD+=" -DLLVM_INCLUDE_TESTS=OFF" |
执行 build 脚本:
1 | chmod 777 ollvm-build.sh |
编译后的二进制文件存放在 obfuscator/build_release 文件夹,在 obfuscator/build_release/bin 中执行 ./clang --version 确定是否编译成功,该 clang 版本为 4.0.1。首先编译一个未混淆的 TestProgram,与后面混淆的结果进行对比。这里没有将 OLLVM 的 clang 链接到 /usr/bin,因此需要指定 obfuscator/build_release/bin 中的clang。
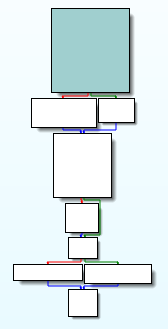
1 | ./clang /tmp/TestProgram.cpp -o /tmp/TestProgram |
在 IDA 中的效果:
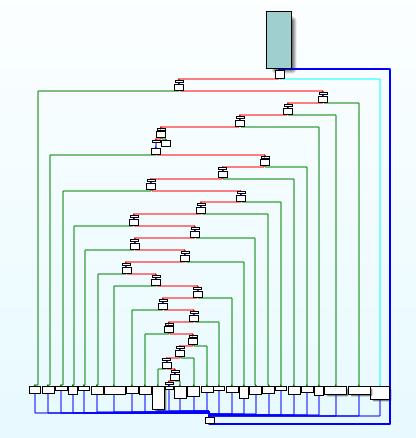
控制流平坦化
1 | ./clang -mllvm -fla -mllvm -split -mllvm -split_num=3 /tmp/TestProgram.cpp -o /tmp/TestProgram_fla |
使用的选项:
-mllvm -fla,激活控制流平坦化-mllvm -split,激活基本块分割-mllvm -split_num=3,指定基本块分割的数量
效果:
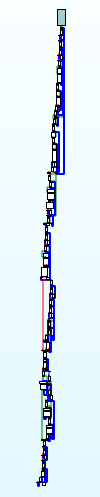
虚假控制流
1 | ./clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 /tmp/TestProgram.cpp -o /tmp/TestProgram_bcf |
选项:
-mllvm -bcf,激活虚假控制流-mllvm -bcf_loop=3,混淆次数,默认1-mllvm -bcf_prob=40,每个基本块被混淆的概率,默认30
效果:
指令替换
1 | ./clang -mllvm -sub -mllvm -sub_loop=3 /tmp/TestProgram.cpp -o /tmp/TestProgram_sub |
选项:
-mllvm -sub,激活指令替换mllvm -sub_loop=3,混淆次数,默认1
指令替换不改变控制流,只是将指令用等价的其他指令替换,指令替换后的 encrypt 函数:
1 | __int64 __fastcall encrypt(unsigned __int8 *a1, char *a2) |
控制流平坦化(Control Flow Flattening)
指的是将正常控制流中基本块之间的跳转关系删除,用一个集中的分发块来调度基本块的执行顺序。这是以函数为单位进行的混淆方式。
结构:
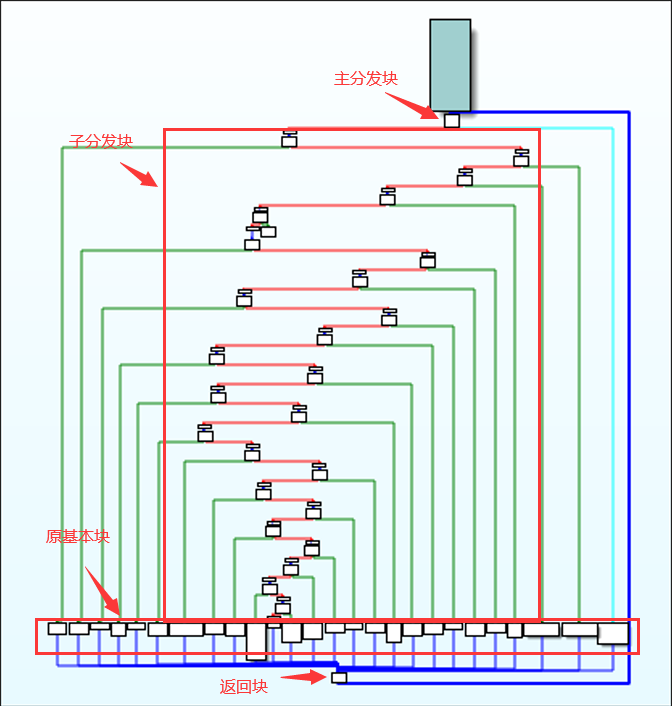
分析进行过控制流平坦化混淆的程序时,在不知道基本块执行顺序的情况下,分别分析每个基本块难度很高,而且如果希望了解执行顺序,就必须分析分发块的调度逻辑,这是非常困难的。
步骤
保存原基本块。将除入口块之外的基本块保存到 vector 容器中,方便后续处理。如果入口块的终结指令是条件分支指令,则将该指令单独分离出来作为一个基本块,放到 vector 容器的最前面。这样可以保证入口块只有一个后继块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16vector<BasicBlock*> origBB;
for(BasicBlock &BB: F){
origBB.push_back(&BB);
}
origBB.erase(origBB.begin());
// 删除第一个基本块(入口块)
BasicBlock &entryBB = F.getEntryBlock();
if(BranchInst *br = dyn_cast<BranchInst>(entryBB.getTerminator()){
if(br->isConditional()){
BasicBlock *newBB = entryBB.splitBasicBlock(br, "newBB");
origBB.insert(origBB.begin(), newBB);
}
}
// 如果入口块的终结指令是条件跳转,将其分离成一个单独的基本块并放到 vector 开头创建分发块和返回块。分发块负责调度基本块的执行顺序,并且需要建立入口块到分发块的绝对跳转。基本块执行完后都需要跳转到返回块,返回块直接跳转回分发块。
1
2
3
4
5
6
7
8BasicBlock *dispatchBB = BasicBlock::Create(F, getContext(), "dispatchBB", &F, &entryBB); // 创建到入口块之前
BasicBlock *returnBB = BasicBlock::Create(F.getContext(), "returnBB", &F, &entryBB);
BranchInst::(Create(dispatchBB, returnBB));
entryBB.moveBefore(dispatchBB); // 重新将入口块移动到最前
// 去除第一个基本块结尾的跳转
entryBB.getTerminator()->eraseFromParent();
// 建立第一个基本块到 dispatchBB 的跳转
BranchInst *brDispatchBB = BranchInst::Create(dispatchBB, &entryBB);实现分发块调度。首先在入口块中创建并初始化 switch 变量,在调度块中插入 switch 指令实现分发调度。随后将基本块移动到返回块之前,并分配随机 case 值,并将其添加到 switch 指令的分支中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 在入口块插入 alloca 和 store 指令创建和初始化 switch 变量,初始值为随机
int randNumCase = rand();
AllocaInst *swVarPtr = new AllocaInst(TYPE_I32, 0, "swVar.ptr", brDispatchBB);
new StoreInst(CONST_I32(randNumCase), swVarPtr, brDispatchBB);
// 在分发快插入 load 指令读取 switch 变量
LoadInst *swVar = new LoadInst(TYPE_I32, swVarPtr, "swVar", false, dispatchBB);
// 在分发块插入 switch 指令实现基本块的调度
BasicBlock *swDefault = BasicBlock::Create(F.getContext(), "swDesfault", &F, returnBB);
BranchInst::Create(returnBB, swDefault);
SwitchInst *swInst = SwitchInst::Create(swVar, swDefault, 0, dispatchBB);
// 将基本块插入到返回块之前,并分配 case 值
for(BasicBlock *BB, origBB){
BB->moveBefore(returnBB);
swInst->addCase(CONST_I32(randNumCase), BB);
randNumCase = rand();
}实现调度变量自动调整。在每个原基本块最后添加修改 switch 变量值的指令,便于返回分发块之后能够正确执行到下一个基本块。删除原基本块末尾的跳转,使其结束执行后跳转到返回块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 在每个基本块后添加修改 switch 变量的指令和跳转到返回块的指令
for(BasicBlock *BB: origBB){
// 无后继块,说明函数在这里返回,不需要处理
if(BB->getTerminator()->getNumberSuccessors() == 0){
continue;
}
// 无条件跳转,有一个后继,新增一条修改 switch 变量的指令,修改为它原来后继块对应的 case 值
else if(BB->getTerminator()->getNumberSuccessors() == 1){
BasicBlock *sucBB = BB->getTerminator()->getSuccessor(0);
BB->getTerminator()->eraseFromParent();
ConstantInt *numCase = swInst->findCaseDest(sucBB);
new StoreInst(numCase, swVarPtr, BB);
BranchInst::Create(returnBB, BB);
}
// 条件跳转,有两个后继。获取原来的跳转指令,用 select 替换,将对应的不同 case 值存储到 switch 变量中。
else if(BB->getTerminator()->getNumberSuccessors() == 2){
ConstantInt *numCaseTrue = swInst->findCaseDest(BB->getTerminator()->getSuccessor(0));
ConstantInt *numCaseFalse = swInst->findCaseDest(BB->getTerminator()->getSuccessor(1));
BranchInst *br = cast<BranchInst>(BB->getTerminator());
SelectInst *sel = SelectInst::Create(br->getCondition(), numCaseTrue, numCaseFalse, "", BB->getTerminator());
BB->getTerminator()->eraseFromParent();
new StoreInst(sel, swVarPtr, BB);
BranchInst::Create(returnBB, BB);
}
}修复 PHI 指令和逃逸变量。平坦化之后原有的基本块的前驱块都变成了分发块,因此 PHI 指令发生了损坏。逃逸变量指的是在一个基本块中定义,在另一个基本块中引用的变量。源程序中某些基本块可能引用之前某个基本块中的变量,平坦化之后原基本块之间没有确定的前驱后继关系,因此某些变量的引用可能损坏(这里指的应该是寄存器变量)。修复方法是,将 PHI 指令和逃逸变量都转化为内存存取指令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25void Flattening::fixStack(Function &F){
vector<PHINode*> origPHI;
vector<Instruction*> origReg;
BasicBlock &entryBB = F.getEntryBlock();
for(BasicBlock &BB:F){
for(Instruction &I: BB){
if(PHINode *PN = dyn_cast<PHINode>(&I){
origPHI.push_back(PN);
}else if( (!(isa<AllocaInst>(&I) && I.getParent() == &entryBB)
// 如果在入口块中进行 alloca,则不是逃逸变量
&& I.isUsedOutsideOfBlock(&BB)
// 不满足上面的条件,又在当前块外使用,则是逃逸变量
{
origReg.push_back(&I);
}
}
}
for(PHINode *PHI: origPHI){
DemotePHIToStack(PH, entryBB, getTerminator());
}
for(Instruction *I: origReg){
DemoteRegToStack(*I, entryBB.getTerminator());
// LLVM 中变量又叫做虚拟寄存器
}
}
实现
原作者的代码在我的环境中编译或者运行时会报错,进行了多处修改。
在之前工程的基础上,在 Transform/include 目录中新建 Utils.h 文件:
1 |
|
Transform/Flattening.cpp:
1 | #include "llvm/IR/Function.h" |
Transform/src/Utils.cpp:
1 |
|
在 CMakLists.txt 中添加 Utils.cpp 和 Flattening.cpp:
1 | project(OLLVM++) |
修改 Build.sh 脚本:
1 | cd ./Build |
编译完成后使用 IDA 观察混淆后的控制流。
虚假控制流(Bogus Control Flow)
指的是向正常控制流中插入若干不可达基本块和由不透明谓词造成的虚假跳转,产生大量垃圾代码来干扰分析的混淆。它以基本块为单位进行混淆,每个基本块要经过分裂、克隆、构造虚假跳转等操作。
步骤
- 基本块拆分。将基本块拆分为头部、中部和尾部三个基本块。通过 getFirstNonPHI 函数获取一条指令,该指令之后没有 PHI 指令,以该指令作为头部和中部的界限进行分割;源基本块的终结指令为中部和尾部的界限进行分割。
- 克隆中部的基本块。注意对原基本块变量的引用需要修改,使用 CloneBasicBlock 的 ValueToValueMap 返回值进行修改。
- (可选)对克隆后的基本块进行变异,插入一些随机指令。OLLVM 中有这个操作。
- 构造虚假跳转。将头部到中部和中部到尾部的绝对跳转修改为条件跳转,并添加克隆的中部基本块到原中部基本块的绝对跳转。
实现
新建 Transform/src/BogusControlFlow.cpp:
1 | #include "llvm/IR/Function.h" |
在 Utils.h 中添加 createCloneBasicBlock 函数的声明:
1 |
|
并在 Utils.cpp 中添加实现:
1 | #include "Utils.h" |
测试完成后使用 IDA 观察控制流。
指令替代(Instruction Substitution)
将正常的二元运算指令(加减法、位运算等)替换为等效但更加复杂的指令序列,达到混淆计算过程的目的。指令替代不改变控制流,但会使运算过程难以分辨。
加法替换
a = b + c 的替换方案:
addNeg,a = b - (-c)addDoubleNeg,a= -(-b + (-c))addRand,r = rand(); a = b + r; a = a + c; a = a - raddRand2,r = rand(); a = b - r; a = a + b; a = a + r
减法替换
a = b - c 的替换方案:
subNeg,a = b + (-c)subRand,r = rand(); a = b + r; a = a - c; a = a - rsubRand2,r = rand(); a = b - r; a = a - c; a = a + r
与替换
a = b & c 的替换方案:
andSubstitute,a = (b ^ ~c) & bandSubstituteRand,a =(b | ~c) & (r | ~r)
或替换
a = b | c 的替换方案:
orSubstitute,a = (b & c) | (b ^ c)orSubsitituteRand,a =(b & ~c) & (r | ~r)
异或替换
a = b ^ c 的替换方案:
xorSubstitute,a = (~a & b) | (a & ~b)xorSubstituteRand,a = (b ^ r) ^ (c ^ r) <=> a = (b & r | b & ~r) ^ (c & r | c & ~r)
乘法替换(待续)
实现
添加 Transform/src/Substitution.cpp:
1 | #include "llvm/IR/Function.h" |
在 Utils.h 中加入 CONST 宏:
1 |
|
在 test.sh 中增加测试:
1 | cd ./Build |
编译完成后,比较混淆前后的 encrypt 函数。混淆前:
1 | .text:0000000000401180 ; =============== S U B R O U T I N E ======================================= |
混淆后:
1 | .text:0000000000401174 ; --------------------------------------------------------------------------- |
可以观察到,执行指令替换后的程序运算过程复杂程度非常高。
随机控制流(Random Control Flow)
是虚假控制流的一种变体,通过克隆基本块以及添加随机跳转(跳转到功能相同的两个基本块之一)来混淆控制流。由于不存在不可待基本块和不透明谓词,因此用于去除虚假控制流的手段无效。随机的跳转和冗余的不可达基本块导致了大量垃圾代码,干扰分析,并且 rdrand 指令可以干扰某些符号执行引擎的分析。
随机控制流也以基本块为单位进行混淆。
步骤
- 基本块拆分。同虚假控制流。
- 基本块克隆。这里可以对基本块进行编译,但不能修改基本块的功能。这里需要修复逃逸变量,因为任何执行流都可能执行到。
- 构造随机跳转。把生成随机数的指令插入到入口块,并在入口块后插入基于随机数的随机跳转指令。其中随机数指令可以使用 LLVM 的内置函数 rdrand。然后插入随机跳转。并对随机变量进行等价变换使其更加复杂。
- 构造虚假随机跳转。构造克隆块和原块互相之间和两者到结束块的跳转,但控制跳转时判断的变量,使克隆和原接你快都跳转到结尾的块。
实现
新增 Transform/src/RandomControlFlow.cpp:
1 | #include "llvm/IR/Function.h" |
修改 CMakeList.txt,添加新增的文件:
1 | project(OLLVM++) |
修改 test.sh,添加新的测试:
1 | cd ./Build |
test.sh 中,llc -filetype=obj -mattr=+rdrnd --relocation-model=pic IR/TestProgram_rcf.ll -o Bin/TestProgram_rcf.o手动编译,否则无法找到 rdrand 指令,--relocation-model是必须的,否则会出现以下错误:
1 | /usr/bin/ld: Bin/TestProgram_rcf.o: relocation R_X86_64_32 against symbol `input' can not be used when making a PIE object; recompile with -fPIE |
完成后的控制流与虚假控制流类似,但是执行流程是随机的。
常量替代(Constant Substitution)
将二元运算指令中使用的常熟,替换为等效但更加复杂的表达式,来达到混淆计算过程或某些特殊常量的目的(比如 TEA 加密中使用的常量 0x9e3779b 可以替换为 12167*16715 + 18858*32146 - 643678438)。
目前只实现了整数常量的替换,因为浮点替换会造成舍入。整数替换与位数有关,目前只实现了 32 位整数的替换,可以拓展至任意位。
常量替代可以进一步扩展为常量数组替代和字符串替代,常量数组替代可以抹去 AES 或 DES 等加密算法中的特征数组,字符串替代可以防止分析者通过字符串定位关键代码。
思路比较简单,对操作数类型为 32 位整数的指令进行替换,替换方案有两种:
- 线性替换。val -> ax + by + c,a, b 为随机常量,x, y 为随机全局变量,c = val - (ax + by)
- 按位运算替换。val -> (x << 5 | y >> 3) ^ c,x, y 为随机全局变量,c = val ^ (x << 5 | y >> 3)
实现
添加 Transform/src/ConstantSubstitution.cpp:
1 | #include "llvm/IR/Function.h" |
在 CMakeList.txt 中添加新的源文件:
1 | project(OLLVM++) |
在 test.sh 中添加新的测试:
1 | cd ./Build |
待实现:
- 任意位整数替换
- 替换数组
- 替换字符串